Technologies
The World Avatar™ is an ecosystem of tools and services that can be used to create an individual digital twin, or network of connected digital twins, to provide a platform of data and model interoperability. This platform can then be used to connect disparate data silos, chain together complex models, provide querying services via intelligent agents, and host cutting edge visualisation and analysis tools. To achieve this, a number of industry standard technologies are used in conjunction with scriptable, customisable environments to easily spin up any number of platforms to meet the requirements of the use case.
Thanks to the use of The World Avatar™’s customisable, linked virtual environments, any number of tools and services can be administered together, and new tools can be added as easily as putting together a few configuration files.
Through the use of containerisation, The World Avatar™ has also been designed to run agnostically of the specifications, and locations, of the physical hardware hosting it. This allows the system to easily be distributed across a number of machines, improving reliability and efficiency; this also allows The World Avatar™ to sit behind any number of security safeguards, protecting the owner’s data and providing need-to-know access.
A brief introduction to the core technologies commonly used throughout The World Avatar™ is presented below.
Connect
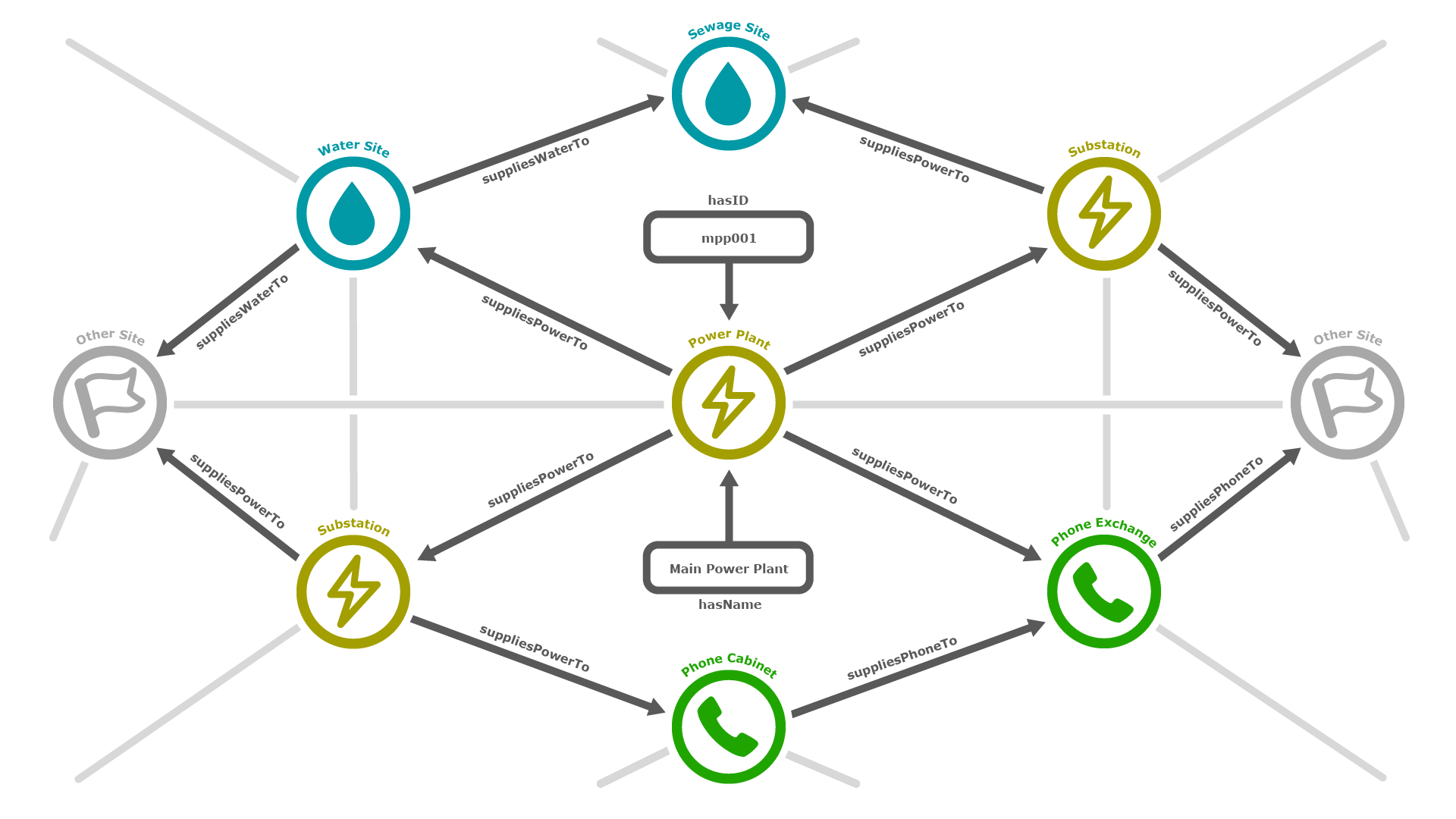
Data sets provided by The World Avatar™ are (primarily) stored internally as knowledge graphs. Each knowledge graph can store a collection of interlinked descriptions detailing the concepts, entities, relationships, and attributes of a data set. Knowledge graphs allow us to put data into context by marking up entries using semantic metadata and linking entities together; this then provides a solid framework for integrating further data, sharing data, and running analyses.
Knowledge within the graph is semantically marked up via the use of an Ontology. Ontologies are a formal naming and definition of the categories, properties, and relationships that encompass the data.
When used in conjunction, knowledge graphs and ontologies allow The World Avatar™ to…
- Provide data in a human and machine readable format that can be processed in an unambiguous and efficient manner.
- Form a traversable network of data, easily recognising and distinguishing entities in the collected data.
- Perform inference, allowing for the discovery of new relationships or inconsistencies in the data.
- Tailor the knowledge to various domains and industries, allowing for a wide range of applications.
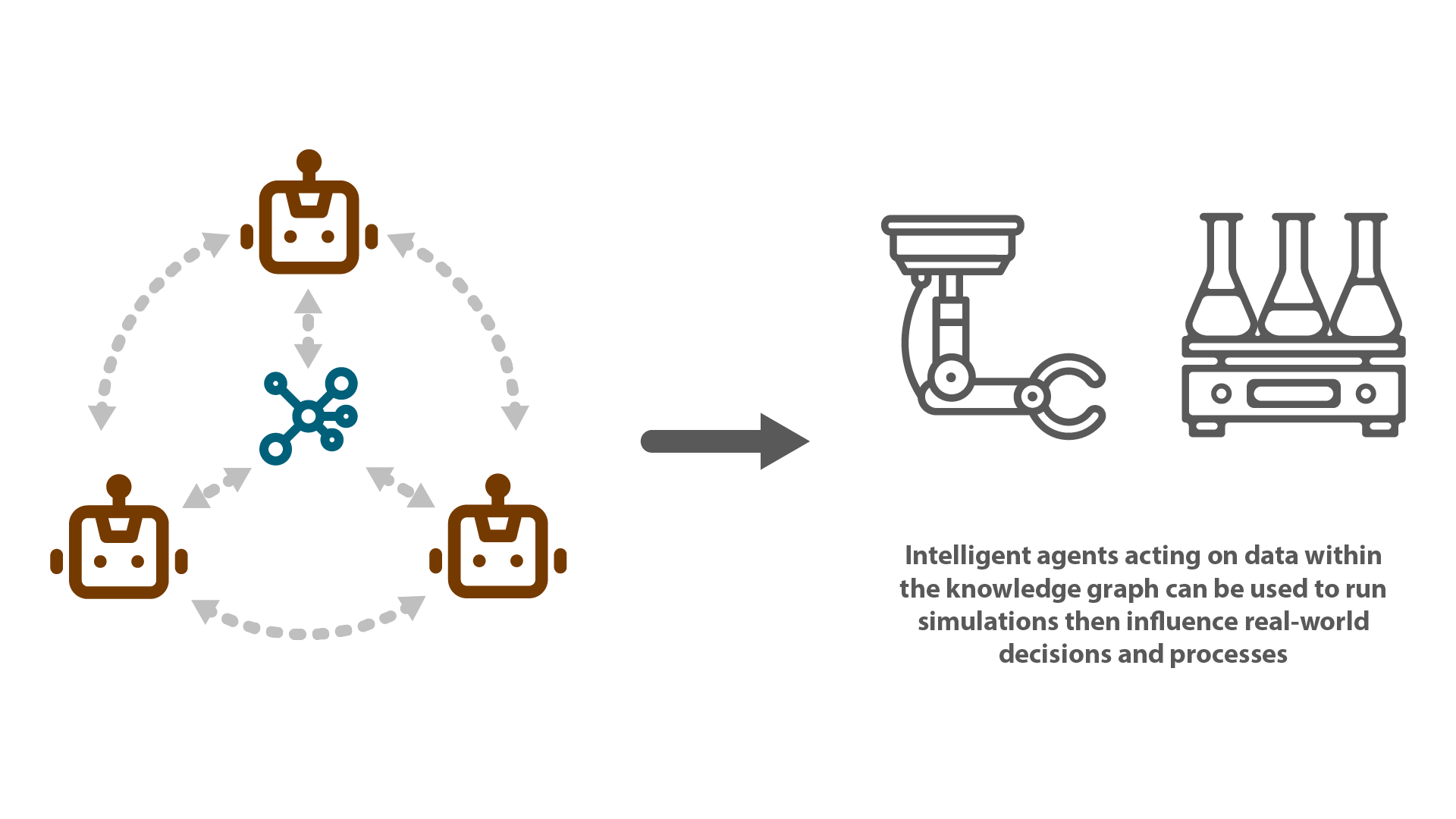
Control
In addition to data hosting services, and computational models, The World Avatar™ system is also capable of hosting a distributed network of microservices, and can establish connections to external services or APIs. This flexibility allows The World Avatar™ to make use of any findings to change real-world processes, and effectively inform key business decisions.
Microservices can be created to easily query data from the knowledge graphs (via an easy to use library provided by The World Avatar™), and use this for a number of output functions like generating real time visualisations, business reports, or controlling real-world hardware.
Case studies have already been carried out using cutting-edge laboratory equipment, controlling automated experiments via the results of simulations populated by data from, and executed within, The World Avatar™. Check the Case Studies page for more details.
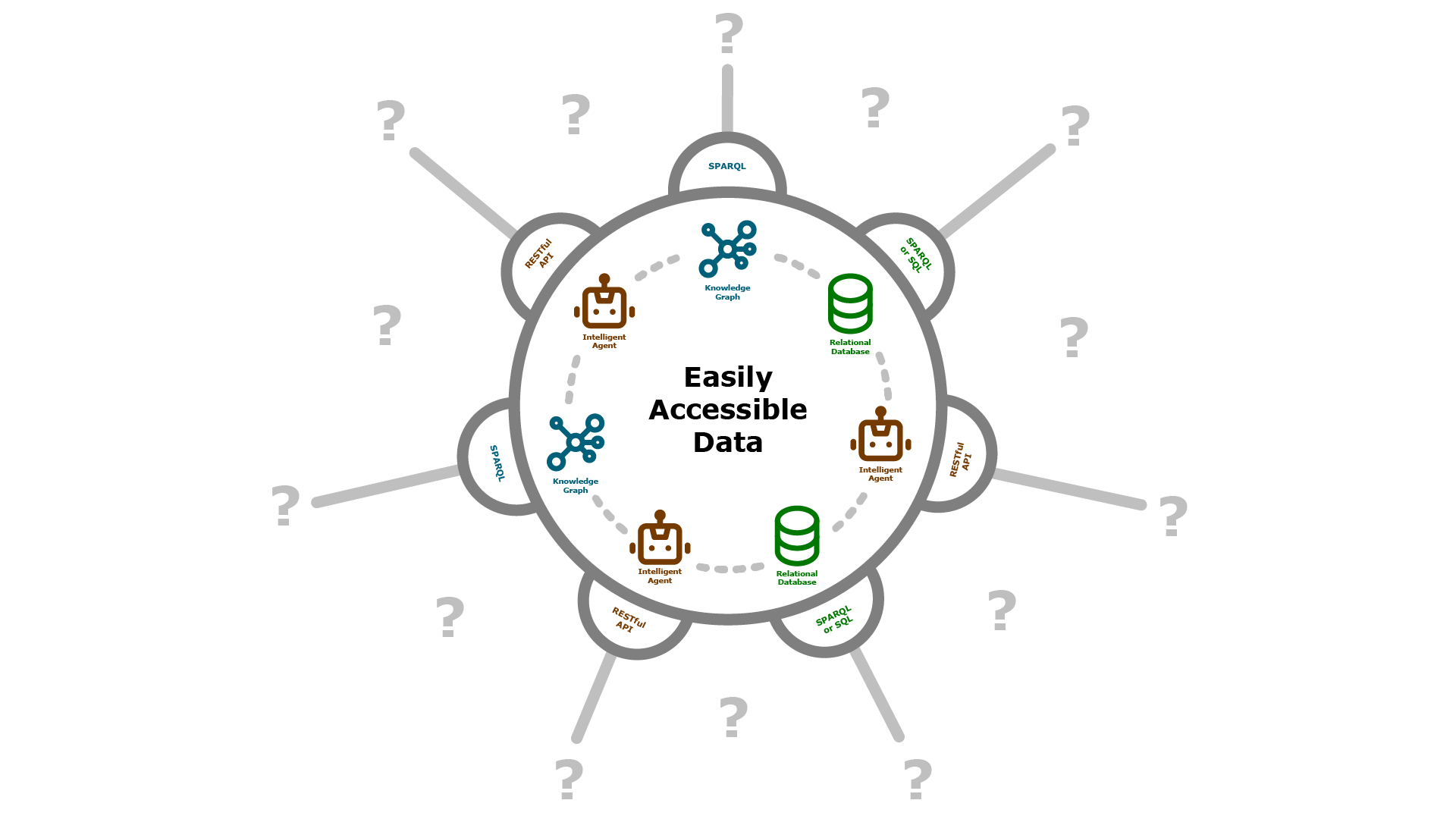
Query
The World Avatar™ provides a number of methods to allow both internal and external services query data from its knowledge graphs. Data, and metadata, stored in databases tailored for graph data (known as triplestores) can be queried through the use of the W3C standard query language, SPARQL.
SPARQL is the industry standard query language and protocol for linked, semantically tagged, data. Having been designed to query a great variety of data, it can efficiently extract information hidden in non-uniform data and stored in various formats and sources.
In cases where more esoteric data is needed (such as geospatial data, or high frequency sensor readings), The World Avatar™ is also able to make use of industry standard relational databases (such as PostGIS, MySQL, or InfluxDB). These tools offer optimisations specific to certain data formats. In addition to offering direct SQL endpoints for relational databases, The World Avatar™ is able to make use of virtual knowledge graph services like Ontop, to provide SPARQL endpoints for the same data.
Intelligent agents running within the system can also be queried using standard a RESTful API to return calculated, filtered, sorted, or combined datasets. This allows easy access to all data within the system, regardless of how it is stored.
Through the use of ontologies, and easily queryable knowledge graphs, The World Avatar™ also supports semantic inference. Semantic inference is the process by which new data is added to a graph, created from the existing data; these insights come in the form of new relationships, providing connections in the data that were previously unobserved.
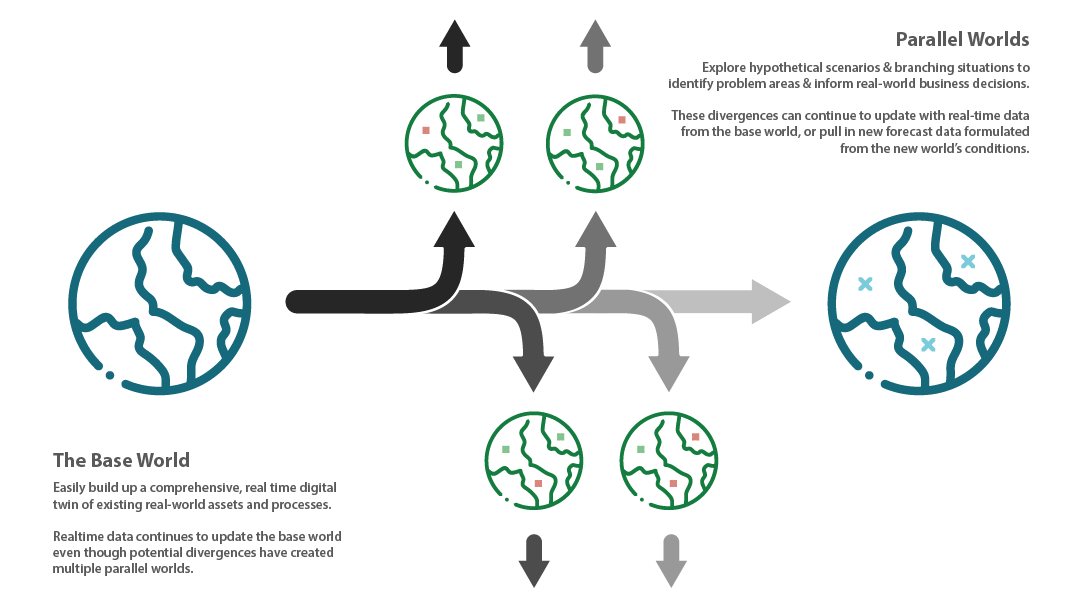
Imagine
Effectively storing and presenting existing data is often mission critical, but extending knowledge to explore “What If?” scenarios can help inform key business decisions and prevent possible loss of service or revenue in future worst-case situations. The World Avatar™ supports this functionality by building on the existing real-world data (known as the “base world”) to also present any number of possible scenarios (known as “parallel worlds”). These parallel worlds can then continue to evolve over time, diverging from the state of the base world whilst maintaining the ability to explore data across both space and time.
Through the use of cloning and editing existing data sets, The World Avatar™ can re-run any computational models (such as failure or output predictions) and produce new sets of outputs specific to a new input condition. This allows users to perform scenario analysis with their data, such as:
- How does the net output of the system change if this site goes offline?
- What happens if a particularly devastating storm hits this part of the country?
- How many people would be effected by an outage at this power plant?
Each parallel world scenario can be explored and analysed through the use of The World Avatar™’s visualisation system. This system provides an easy-to-explore geographical representation of the data within the scenario, as well as a full analytics dashboard that can be used to deeper investigate the raw output data.